M5Stack
If you are an ESP32 WiFi MCU fan, chances are you already know the M5Stack kits. M5Stack is a very cool platform that consist of a handful of different ESP32 based controller boards, and a whole lot of sensors ready to plug to your controller of choice. All the devices are nicely packaged and ready to use in Arduino IDE or UiFlow: a web based IDE supporting Blocky and micro Python languages.
 |
| What's this? |
UiFlow is really cool, you just connect sensors to your core module and power it on. It then connects to the cloud, so you can open the UiFlow IDE on your browser and connect to your module. Then you grab some blocks, plug them to build your application, hit RUN button and the program is instantly downloaded and run on your core. It even allows switching your program from Blocky to Python with one click, how cool this is for teaching programming and robotics to kids?
 |
| Hello, is anybody there? |
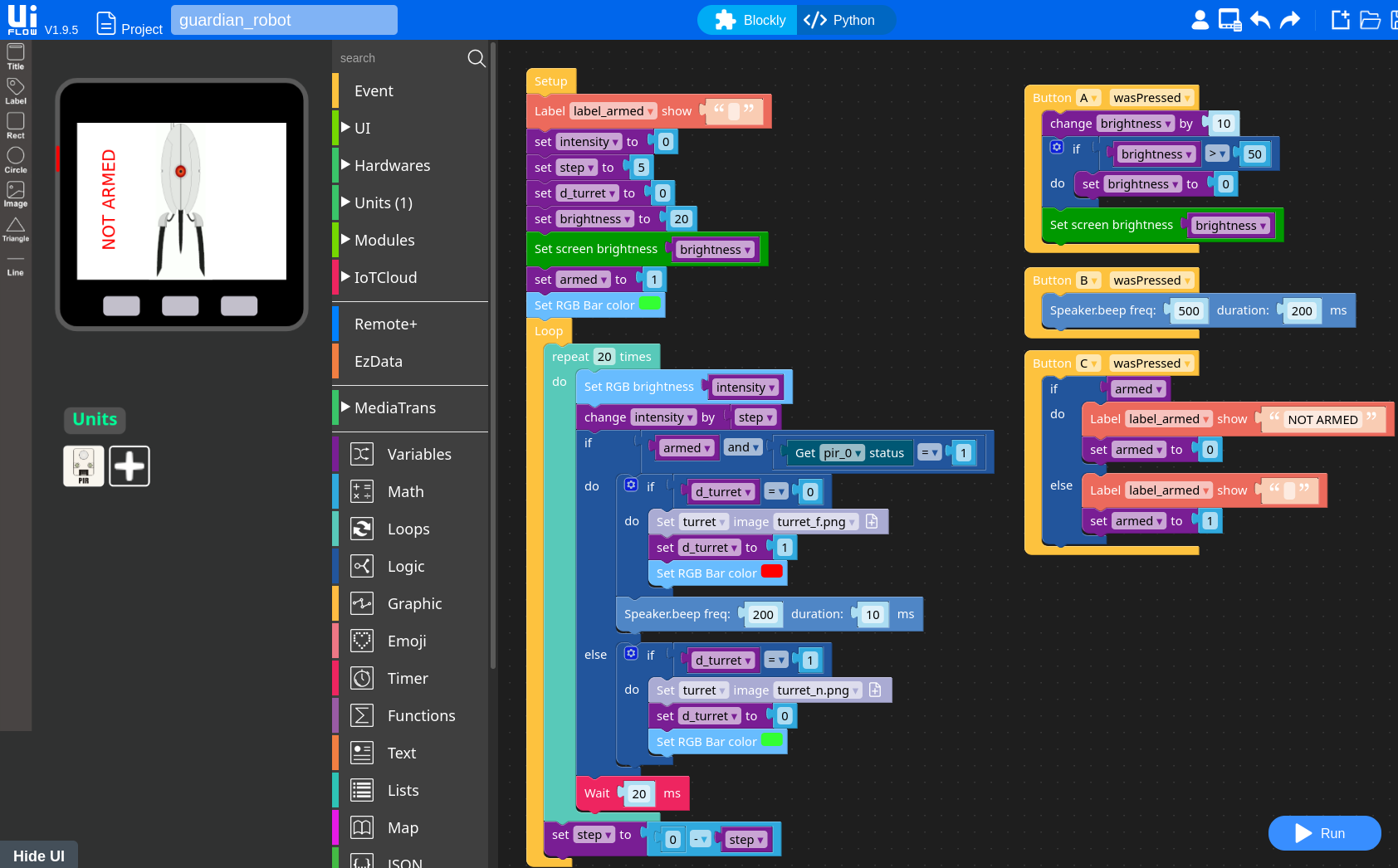
So, if you want to attach a PIR sensor to the M5Stack FIRE core to build a sentry turret with your son (as I did and you can see in the photos above), that's great. But what if you want a more "standard" development environment C/C++ based? Well, you can use Arduino. But what if like me, you are not an Arduino fan and want to use a pure Espressif IoT Development Framework (aka esp-idf)? This is where the fun starts.
esp-idf
You might be wondering why bothering with esp-idf instead of using UiFlow/Arduino. I find UiFlow awesome for learning purposes. But being micro Python running on an ESP32 under the hood, I find performance not that great, and the language a bit limited when you want to do complex tasks and there is not an already made module doing it for you.
With Arduino, for me the problem is similar. You can use Arduino to do complex programs. But usually Arduino shines when you do not want/need to care about the underlying hardware: registers, interrupts, DMA, etc. When you need to do a very specific use of the hardware, the way Arduino tries to hide the complex details will get in the way and make things more difficult. Also I have found several times Arduino modules with a not that good code quality.
But what about esp-idf? For me it's the real deal for ESP32 development: it's an evolution of ESP8266_RTOS_SDK (for their older ESP8266 chips). esp-idf is just the compiler, a Python build script (using CMake under the hood) and a whole lot of ready to use libraries, all of them Open Source (excepting the ESP32 WiFi/BT binary blobs). It includes the good-old FreeRTOS for task management, lwIP as network stack, a bunch of ready to use protocols (MQTT, HTTPS client and server, SMPT, MDNS, etc.), peripheral libraries for all the usual suspects (GPIO, ADC, DAC, neopixel LEDs, SPI, I2C, UART, etc.) and a lot more. The build system and all these components are very well documented, and most of the libraries have ready to build and test examples!
For me this is the ideal way of making an SDK for embedded development: use standard tools (like CMake and menuconfig) and take care of integrating as many useful open source libraries as you can. Then let the user choose how to integrate this into their favorite editor/IDE!
I will not cover how to install and use esp-idf. The official documentation has a nice installation guide, or alternatively if you are a Docker user, you can try my ready to go image. Just make sure you are using the v4.4 branch:
Adjust the paths above as needed by your environment, and put these lines in a script if you are going to use this image regularly!
It's all about peripherals
Using esp-idf for ESP32 development is great, but there is a catch: esp-idf will support out of the box some of the peripherals included in your core. But not all, specially it does not support the screen and sensors external to the ESP32. So you want to acquire some accelerometer readings and print them on a nice graph? Then you have to work a bit more. Or at least you had until I decided to step in ^_^. I have gathered in one place all you need to add to esp-idf to support all the peripherals included in the M5Stack FIRE kits. Also included is an example application showing how to use it all. You can find this in the idf-M5Stack GitLab repository.
If you already have esp-idf installed, this is all you need. Plug your M5Stack controller and build and flash the example application:
That's all, if everything works, when the app boots, it will beep twice and then you should see on the screen a 3-line graph plotting the gyroscope readings, three bars showing the magnetometer state and a spinner with a number inside representing the current battery capacity. Pressing A button will change the screen brightness. If your module has the dual LED bar, it will show a multicolor LED chase effect. Isn't it nice for a 350 LoC pure C application?
 |
| Move me! |
If you got compile errors, make sure you are using the 4.4 branch of esp-idf, it is the one I used to build the repository. Below I will enumerate the supported peripherals and detail their support status. Read the repository README.md file for more details!
Screen
The 320x240 IPS screen is supported via the Light and Versatile Graphics Library (LVGL). This library is extremely nice and will make you wish you had a touch interface if, like me, you have a core without one. You can create all kind of widgets with just a few lines of code, it supports themes, custom styles, several fonts... really neat piece of software.
The screen backlight is not managed by the LVGL library itself, but is also supported through the LVGL ESP driver.
Flash
The 16 MiB flash is directly supported by IDF, just needs to be properly configured in menuconfig. The framework takes care of this, so you should have no problem.
PSRAM
The 4 MiB SPI PSRAM is directly supported by IDF. Again it just needs to be enabled in menuconfig, and the framework will do it for you.
Pushbuttons
Pushbuttons A, B and C are directly connected to GPIO pins 39, 38 and 37. Thus they are directly supported using the IDF GPIO functions. You can use standard esp-idf APIs to control them via polling or interrupt.
Dual LED bar
The cool dual LED bar present in M5Stack FIRE kits is directly supported by IDF using the RMT driver and the component included with the led strip example. You can see the example code to learn how it works.
6-axis IMU MPU6886
The IMU is supported using a tiny driver I wrote (initially for the M5Atom Matrix core). It is a bit bare-bones, but for simple use cases it just works.
Magnetometer BMM150
This 3-axis digital geomagnetic sensor is supported using the Bosch Sensortec BMM150 Sensor API. It uses the upstream code directly from the manufacturer, with a bit of glue logic provided by esp_bmm150 repository.
Speaker
The speaker is direclty driven by the DAC using the GPIO 25 pin. The example program uses the esp-idf cosine wave generator API to beep it twice.
Microphone
The microphone is connected to the ADC using GPIO 34. You can browse the esp-idf ADC examples to learn about how to use it.
Battery readings
M5Stack Core modules manufactured after march 2018 manage battery charging using an IP5306 variant connected to the I2C bus. Unfortunately there is no complete documentation of this chip as of today (only a partial datasheet in Chinese, for more information read here). If your board supports this charge IC, the demo application shows the battery level (in 25% steps: 25, 50, 75 or 100) in the center of the spinner widget. If the chip is not found/supported, a '?' character will be shown instead.
microSD card
Unfortunately, things here get a bit messy. The screen and the microSD card share the same SPI bus. This, along with the way the LVGL ESP32 driver works, causes a conflict with SPI bus initialization. Don't worry, this can be solved, but it requires a tiny modification in the LVGL driver code, and has a small performance hit. The fix is explained in the README.md file, so read it if you need the microSD card support. But for applications that do not need it, it is better not enabling the support, to avoid the performance hit on the screen interface. The microSD card code is not included in the master branch, but if you need it, you can checkout the sdcard branch in the repository to have a look.
And that's all, using this framework you should be able to build applications supporting every bit of hardware available on the M5Stack FIRE boards! If you want to plug them some more modules, you will have add support yourself though. Some modules like the PIR are trivial to support (since you just have to read a GPIO pin), but others can be more challenging. Anyway, where is the fun if everything is already done?
Happy hacking!




